
“Whoever builds it will own the entire AI pricing infrastructure.”

What is “it?”
Jeff Bezos built Amazon on SSL, making it safe to buy online.
AI is built on tokens. But tokens fail in agentic workflows, where much of the work happens off-screen and generates no tokens for billing.
So the future of AI isn’t in tokens – it’s in this new paradigm – a control layer that does NOT require changing the model:
- FLOP-based metering
- Customer-controlled governance over spend
- Pre-execution provisioning to reduce cost
- Fixed pricing for work units rather than by-the-seat licensing
All of this is necessary to support agentic workflows which have broken the SaaS pricing model.
And it can be accomplished in a separate layer between the user and the LLM – so there is no need to alter the model.
As a developer told me last week:
“Whoever builds it owns the global AI pricing infrastructure.”
- FLOP-based metering
- Customer-controlled governance
- Pre-execution provisioning
- Pricing
- Normalized Compute Units
1. FLOP-based metering (FBM)
When Thomas Edison built the first electrical systems, they worked—but they didn’t scale because direct current (DC) couldn’t travel more than a mile.

Nikola Tesla solved that with alternating current (AC). Same electricity—different system—and suddenly power could go the distance.
AI cost is hitting the same wall. Tokens can’t “go the distance” agentic AI requires.
Like DC which failed at scale, tokens worked—until they didn’t. Here’s why:
In most agentic workflows, much of the work happens off-screen and generates no tokens for billing. So the compute consumed is not accounted for.
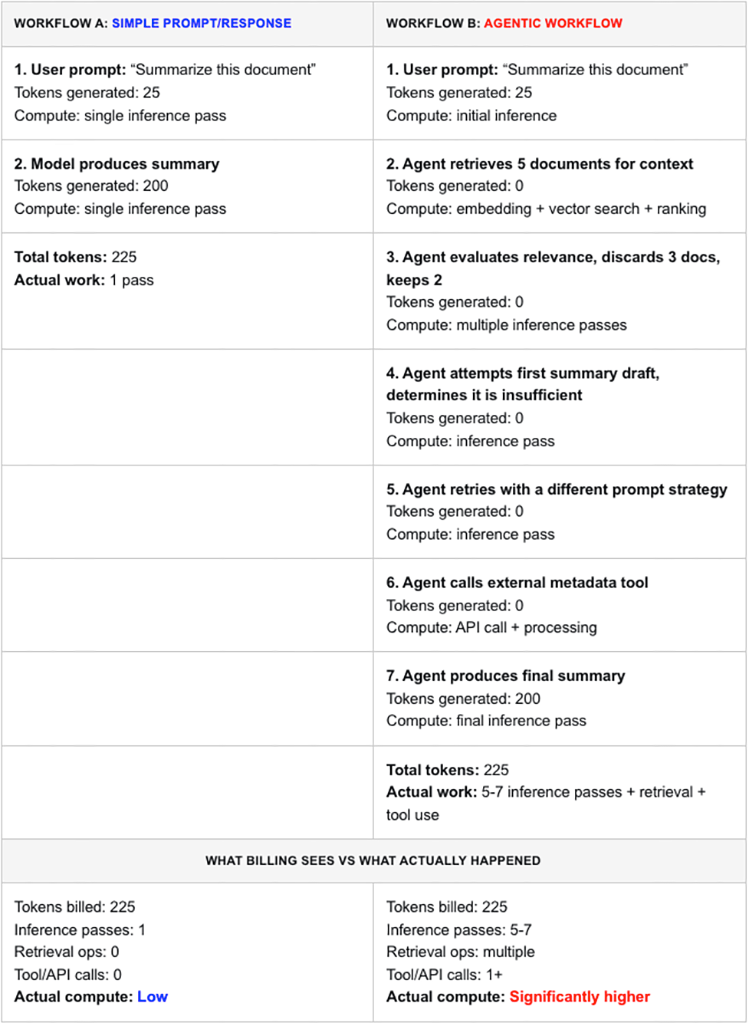


If you are counting tokens, you are flying blind for two reasons
Semantic blindness: Tokens count words, but they don’t understand meaning. A simple request and a complex task may use the same number of tokens — while requiring very different amounts of compute.
Invisibility: Agentic workflows perform work off-screen — retrieval, tool use, iteration — that never becomes tokens at all.
So tokens measure neither the meaning of the work, nor the full amount of work performed.
Consider these two scenarios:
A guy talks to AI for thirty minutes about his girlfriend. He goes on and on…
- How she seems distant.
- How she is slow to respond to texts.
- How she is mysteriously unavailable.
The system dutifully transcribes every word, responds empathetically and consumes a massive number of tokens — all while avoiding the four words a human would scream immediately: SHE’S CHEATING ON YOU!
Now consider a three-word query:
“Is God real?”
Few questions demand more reasoning, context, philosophy and depth. Yet under token-based billing, that interaction may never recover the cost of compute.
And in both cases, look at the asymmetry between input, output and effort. There is no correlation between number of tokens — either in or out — and compute.
To put it in historical context again, using tokens to measure compute is like measuring electricity in horsepower: It didn’t work after machines replaced horses.
Tokens are the horsepower of AI.
Compute is the kilowatt-hour
What FBM actually does
FBM measures the computational work required to produce a result
Not the text written to the screen.
Why this matters
Tokens answer: how much text was generated
FBM answers: how much work was performed
The critical distinction
Compute is driven by reasoning path, not word count.
How FBM works
- Estimate computational workload per request
- Express that work in FLOPs
- Evaluate before, during, and after execution
What FBM enables
- pre-execution estimation
- per-request cost visibility
- enforcement of cost boundaries
Why tokens fail here
Token systems:
- measure output
- infer cost indirectly
- hide variability
FBM: measures execution directly
The consequence
Without a compute-aligned unit: cost cannot be bounded — only approximated
If you’re an engineer and this resonates, we’re looking for a development partner to build this system: signal@revenuemodel.ai – we read every email.
2. Customer-controlled governance
Finance does not need another dashboards more optimization. Finance needs:
- Control before spend occurs
- Enforceable limits
- A unit that reflects actual cost
The new failure mode
AI introduces a structural risk: users and agents can generate cost at scale without intent
This risk did not exist before.
Governance solves this at the source
A customer-controlled control layer enables:
- Limits by user, team, or workflow
- Restriction of high-cost operations
- Enforcement before execution
- Prevention of inference when conditions are not met
- Routing to lower-cost alternatives
What changes
Today: execution happens → cost is discovered
With governance: cost is approved → execution is allowed
Why this matters
Without governance: you do not have control — you have exposure
3. Pre-execution provisioning (G‑PEP)
Governed, pre-execution provisioning (G-PEP) is a control layer that authorizes, constrains, routes, defers, or denies execution before inference occurs.
AI execution becomes: a permissioned economic event
G-PEP explained via a deliberately absurd car analogy
Why it exists
Most systems assume every request executes, cost is handled later
This creates:
- unpredictable spend
- margin compression
- no hard control
G-PEP reverses this: permission first, execution second
What “governed” means
- explicit policy layer
- auditable decisions
- authority to deny execution
Core behavior: per-query provisioning
Every request is evaluated independently.
Outcome:
- full execution
- constrained execution
- low-cost routing
- deferral
- denial
What denial actually means
Denial ≠ no response
It means: no high-cost execution
Instead:
- cached answers
- retrieval results
- summaries
- refinement prompts
Result: user gets value without incurring cost
Key distinction
Routing systems assume execution.
G-PEP decides: whether execution is allowed at all
Where control actually happens
Not after execution.
Not during execution.
Before compute is consumed.
The outcome
- lower peak infrastructure demand
- reduced operating cost
- bounded financial exposure
4. Pricing
AI is being forced into models that don’t fit:
- Seat-based pricing hides cost until margins collapse
- Token pricing exposes cost but makes it unpredictable
One breaks the provider.
The other breaks the customer.
The real requirement: bounded, predictable cost
Customers don’t need perfect pricing. They need:
- predictability
- control
- no surprises
If a CFO cannot forecast it, it does not get approved.
If a user can accidentally create a large bill, it does not get trusted.
Bounded AI pricing
Bounded AI Pricing reframes the problem: AI usage must be bounded before execution, not reconciled after.
Fixed price per work unit – not tokens
Each unit includes a defined allocation of compute.
- Not tokens
- Not abstract usage
- Actual compute capacity, measured via FLOPs and normalized across systems
This aligns pricing with the real cost driver while keeping it predictable.
Customers know:
- what they are paying for
- what is included
- what the system will do
Fixed overage with early detection
When usage exceeds allocation:
- overage pricing is predefined
- alerts occur before limits are reached
- soft caps and throttles prevent runaway usage
No surprise invoices. No retroactive explanations.
The shift
This is not better pricing. This is the difference between bounded cost and open-ended liability.
5. Normalized Compute Unit
NCU is a standardized unit that represents compute consumption in a consistent, comparable form.
It converts raw compute into something usable for:
- pricing
- budgeting
- control
Why normalization is required
Raw compute is not comparable across:
- models
- hardware
- environments
This creates:
- inconsistency
- non-comparability
- unusable metrics
What NCU does
NCU makes compute:
- consistent
- comparable
- stable
How it works
- translate raw compute into a normalized unit
- apply consistently across systems
- enable estimation and enforcement
Relationship to FBM
- FBM = measures compute
- NCU = standardizes it
Together: measurement + usability
Relationship to G-PEP
G-PEP enforces limits.
NCU defines the unit those limits are based on.
Why this matters
Without a normalized unit:
- policies cannot be applied consistently
- budgets cannot be compared
- control cannot be enforced
Final distinction
Tokens: measure text
NCU: measures standardized compute
The outcome
With FBM + NCU + G-PEP:
- compute is measurable
- cost is predictable
- execution is controllable
Final synthesis
This is not five features.
It is one system:
- FBM → measures the work
- NCU → standardizes the unit
- G-PEP → enforces control before execution
- Governance → gives control to the customer
- BAP → packages it into predictable pricing
The shift, stated cleanly
Today: AI executes first, cost is discovered later
This system: cost is defined, approved, and bounded before execution occurs
If you cannot bound cost before execution, you do not have a pricing model — you have financial exposure.
– Published on Thursday, March. 2026
We’re looking for one builder to help turn this into a working system.
signal@revenuemodel.ai
Every email is read.